Web scraping is the act of fetching data from a third party website by downloading and parsing the HTML code to extract data. The web scraping process consists of 1) downloading HTML content of a page, 2) parsing/extracting the data, and 3) saving it into a database for further analysis or use.
Web Scraping Use Cases
Below are a few industries where web scraping is often used:
- News - You can synthesize information from articles on different news sources using extractive or abstractive summaries.
- News Aggregators - You can aggregate articles from different sources such as Reddit, Twitter, The New Yorker, etc.
- Real Estate - You can scrape Redfin or Zillow to create real-time information on housing prices.
- Search Engines - Suppose you want to build an internal search engine for your organization. As a supplement to your internal documents, you might also want to scrape 3rd party data such as eBay listings or user profiles from LinkedIn.
- Travel - You can scrape flight and hotel prices for comparison.
- Online Shopping - Scrape product pages to monitor competitor prices.
- Retail Banking - Aggregate information from various sources such as Mint.com, Credit Union, and E-Trade.
- Data Journalism - LA-based Crosstown is a non-profit that uses data scraping to aggregate real-time data across different data sources to generate unique, data-driven stories.
- Search Engine Optimization - Marketers can optimize SEO content by comparing similar articles found on Google Search results.
- Market Research - Scrape social media sites to identify public opinion (aka sentiment analysis) for trading.
- Lead Generation - Discover new prospects and partners by scraping content online.
- Content Audits - Webmasters can create a sitemap or content audit by scraping pages.
DIY Scraping Libraries
If you are a developer who prefers to build and manage things yourself, then here are a few good libraries for NodeJS.
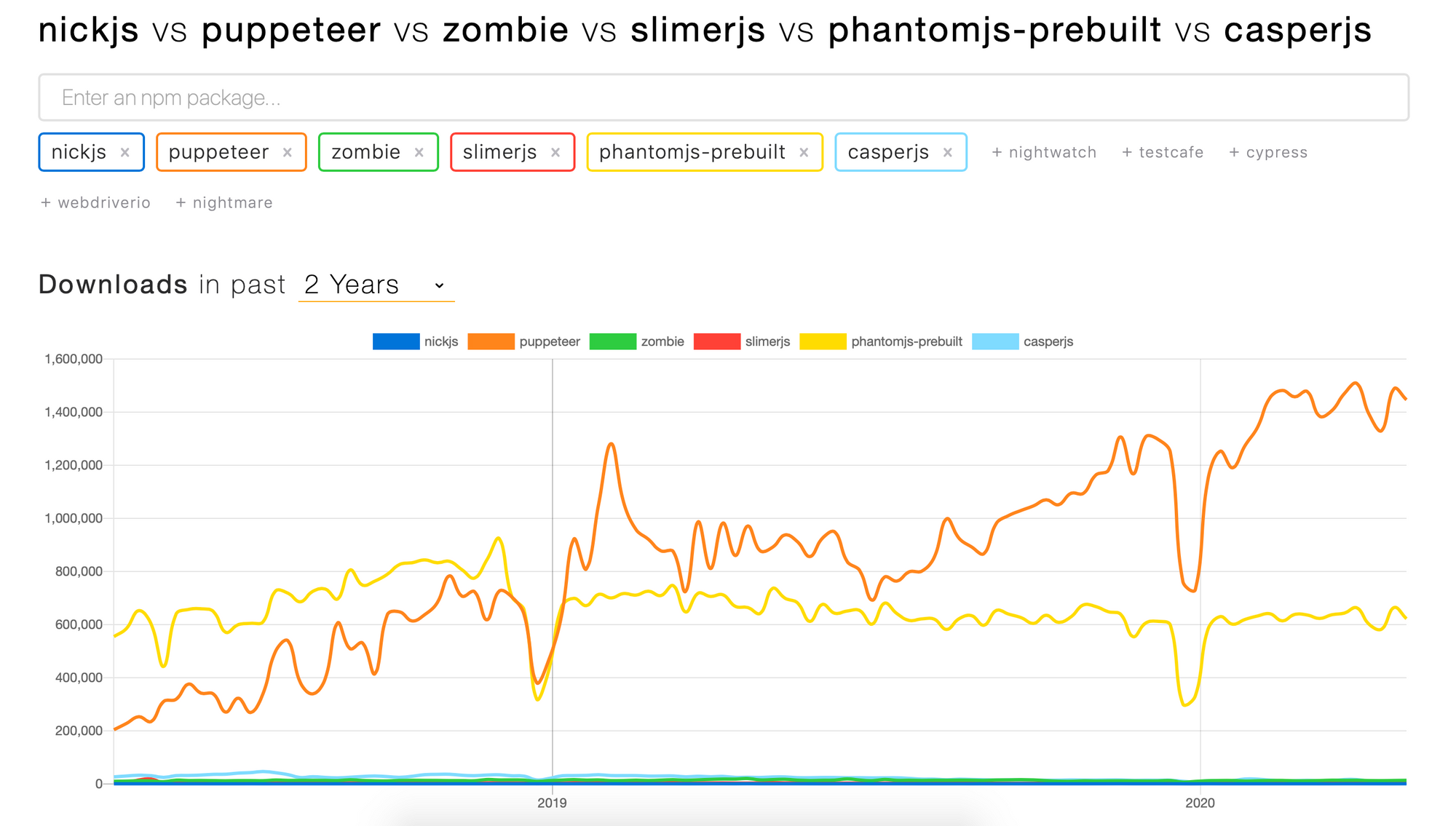
- [NickJS](https://nickjs.org] - Headless browser automation library. This is a good substitute for CasperJS. It works on Google Headless, PhantomJS and CasperJS.
- Google's Pupeteer - Node library which provides a high-level API to control Chrome or Chromium over the DevTools Protocol.
- ZombieJS - Insanely fast, full-stack, headless browser testing using NodeJS.
- SlimmerJS - A scriptable browser like PhantomJS, based on Firefox.
- CasperJS - CasperJS is a navigation scripting & testing utility for PhantomJS and SlimerJS.
Deprecated. - PhantomJS -
Deprecated.
Managed Scapers
Web scraping is somewhat of an art so if you're not ready to manage recaptcha, proxy IP's, "User Agent" and more, try these managed services.
- ScrapingBee - My favorite web scraper to date. It's got great feedback on https://www.producthunt.com/posts/scrapingbee-formerly-scrapingninja and I even wrote a tutorial.
- Crawly by Diffbot - Turn websites into data in seconds. Crawly spiders and extracts complete structured data from an entire website.
- scrapinghub - Offers developers, data scientists, data teams looking to execute web scraping projects. It can handle infinite scroll, multiple pages and Single Page Apps.
- Simplescraper - They offer two great features 1) the ability to generate an API out of scraped data and 2) create recipes that run in the cloud.
- Metadata Scraper API - Extract email, phone number, social profiles, review profiles, and more from just a URL.
- Outwit - Can help you harvest the web into structured data.
More Managed Scrapers
Here are a few more tools in no particular order.
- https://webroots.io
- https://kimonolabs.com
- https://grabby.io
- https://fullcontact.com
- https://emailhunter.co
- https://clearbit.com
- https://toofr.com
- https://import.io
- https://kimonolabs.com
- https://apifier.com
- https://elink.club
- https://www.eliteproxyswitcher.com
- https://www.uipath
- https://cloudscrape.com
- https://commoncrawl.org
- https://www.fminer
- https://scraperwiki.com
- https://nutch.apache
- https://www.ubotstudio
- https://mozenda.com
Even More Resources
You can always find new web scrapers on Product Hunt.



Subscribe to new posts
Processing your application
Please check your inbox and click the link to confirm your subscription
There was an error sending the email